Smart Topic Miner
Smart Topic Miner (STM) is an application that assists the Springer Nature editorial team in classifying the scientific literature in Computer Science in terms of a catalogue of about 15K research topics, with a very high degree of accuracy. This catalogue was itself generated by our team using a highly innovative knowledge discovery algorithm, called Klink. This solution integrates machine learning and semantic technologies to mine millions of publications in Computer Science, identify research fields in this vast collection, and organise them automatically into a taxonomy. Klink was used to produce the Computer Science Ontology (CSO), the largest collection of research topics in Computer Science in the world, which has now been adopted by Springer Nature to support their internal editorial and marketing processes.
Capitalising on CSO, we designed the CSO Classifier, an application which is able to analyse an individual scientific publication in Computer Science and classify it with very high accuracy in terms of the relevant topics selected from the large catalogue of research topics in CSO. The STM application builds on the CSO Classifier and implements an intelligent set-covering algorithm that identifies the set of topics that best describe a collection of scientific contributions.
Specifically, STM takes as input XML files describing one or more publications and returns:
- A taxonomy of the relevant topics drawn from CSO;
- A set of relevant Product Marked Codes (PMCs), Springer Nature internal classification;
- An explanation for each topic, in terms of the text excerpts that triggered the topic identification;
- A list of chapters from the book annotated with topics from CSO.
STM also provides a highly interactive interface, which makes it possible for users to investigate easily the rationale for the classifications proposed by STM. The editors typically explore the output, check why specific topics were inferred by the system, compare them with the annotations produced in previous editions, and include or exclude specific topics or PMCs according to their expertise. The resulting sets of topics and PMCs are eventually included in the metadata of the publications. These are then used for classifying proceedings in digital and physical libraries and consequently improving the discoverability of the publications in SpringerLink and several other digital libraries and third-party sites.
A demo version of STM v.2 is available below, as well as our in-use paper published at the premiere international forum for the Semantic Web and Linked Data community: the International Semantic Web Conference.
Impact of STM
Since 2016, STM has been used routinely by the Computer Science Editorial Team at Springer Nature to annotate all book series covering conference proceedings in Computer Science. The initial prototype has continuously evolved in response to feedback from the users and evolving requirements. In 2019 we released STM 2.0, a completely revamped version of STM that exploits neural networks and word embeddings for identifying the most pertinent topics and takes in account other relevant publications, such as previous editions of a conference. The experiments reported that STM 2.0 yields a better performance in classifying the publications and a much higher usability than the previous versions.
The automation of this complex task has produced both a 75% cost reduction for Springer Nature and also a dramatic improvement in metadata quality. As a result of the latter, downloads in Computer Science from the SpringerLink portal have increased by almost 10 million units, as search engines and visitors to the portal can now identify the relevant scientific content with much greater accuracy, thus benefitting researchers and other consumers of scientific literature all over the world.
Data provided by Springer Nature also indicate that the average number of yearly downloads for Computer Science proceedings in Springer Link has doubled since the introduction of STM in 2016, increasing from 10K to 20K downloads. The figure below shows the average number of yearly downloads for different kinds of SN books published in a specific year. The top line refers to proceedings books in Computer Science before (blue) and after (red) the STM adoption, the intermediate line (grey) refers to the other books in Computer Science, and the yellow line to all the other books. The dotted blue segment branching off the top blue line after 2015 represents the number of expected downloads without STM, estimated on the basis of the other books in Computer Science.
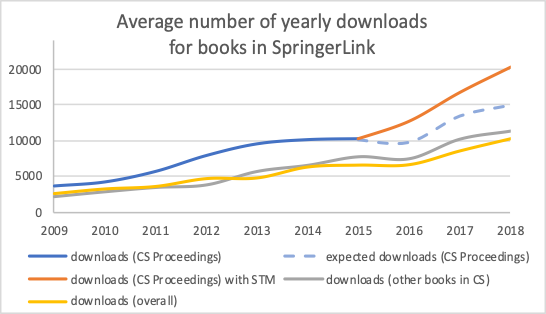
The rate of growth of the publication annotated with STM compares very favourably with the significantly lower 47% average yearly increase for other book series in Computer Science, which in the same period went up from 7.7K to 11.3K, and with other book series that grew from 6.5K to 10.2K. Hence, considering the expected download in 2016-2018 as a baseline, we estimate that the adoption of STM has resulted in almost 10 million additional downloads over the last three years.
These figures show that users, including those based in UK organisations, are more successful in locating valuable content when this has been annotated with STM and are therefore directly benefitting from the high-quality metadata generated by STM. In addition, because most users of the portal access Springer Link content through corporate subscriptions, the net effect is also a lower cost per download for these user organisations, which include practically all UK universities.
Related Link
Related Publications
- STM v.2 – Salatino, A.A., Osborne, F., Birukou, A. and Motta, E. (2019) Improving Editorial Workflow and Metadata Quality at Springer Nature, The 18th International Semantic Web Conference (ISWC 2019), Auckland, New Zealand.
- CSO Classifier – Salatino, A.A., Osborne, F., Thanapalasingam, T. and Motta, E. (2019) The CSO Classifier: Ontology-Driven Detection of Research Topics in Scholarly Articles, TPDL 2019: 23rd International Conference on Theory and Practice of Digital Libraries, Oslo, Norway.
- CSO – Salatino, A.A., Thanapalasingam, T., Mannocci, A., Birukou, A., Osborne, F. and Motta, E. (2019) The Computer Science Ontology: A Comprehensive Automatically-Generated Taxonomy of Research Areas, Data Intelligence.
- STM v.1 – Osborne, F., Salatino, A.A., Birukou, A. and Motta, E. (2016) Automatic Classification of Springer Nature Proceedings with Smart Topic Miner, 15th International Semantic Web Conference, Kobe, Japan.
Related News
Springer Nature and The Open University launch a unique Computer Science Ontology (CSO) – https://group.springernature.com/gp/group/media/press-releases/springer-nature-and-the-open-university-launch-a-unique/16386730