Augur is a novel approach to the early detection of research topics. Augur analyses the diachronic relationships between research areas and is able to detect clusters of topics that exhibit dynamics correlated with the emergence of new research topics.
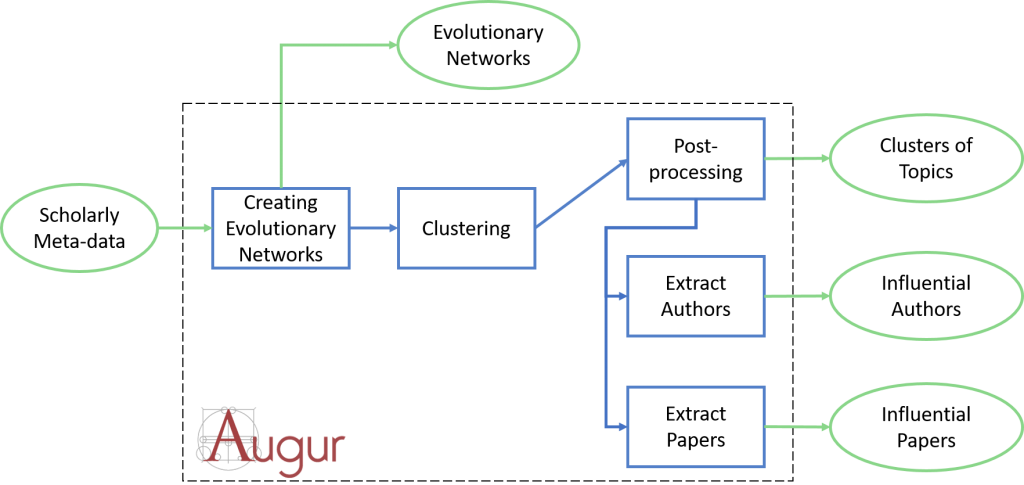
Augur operates in three steps. First, it creates evolutionary networks describing the collaboration between research topics over time. Then it uses a novel clustering algorithm, the Advanced Clique Percolation Method (ACPM), to locate areas of the network that exhibit a significant increase in the pace of collaboration. Finally, it post-processes the results, merging and filtering the resulting clusters. The output of the process are clusters of existing topics (the ancestors of the new topic) that are nurturing a new research area that should shortly emerge. In addition, Augur also returns, for each cluster, a number of significant papers and authors, which can provide more details about the emerging research.
EXAMPLE OF OUTPUT
In the table below, we present an example of a cluster produced by Augur from the topic networks in the period 1998-2002. The cluster (top-left) contains topics such as “world wide web”, “query languages”, “metadata”, “content base retrieval”, and “search engines” that exhibit a strong increment in their pace of collaboration in the period under analysis and match the ancestors of Semantic Search, a topic that debuted in 2003. Therefore, we considered this cluster as correctly predicting Semantic Search. Semantic Search aims to improve search accuracy by understanding the contextual meaning of terms and combines research in semantic technologies and information retrieval. The topics in bold are the direct ancestors of semantic search, but, even among the other ones, we find many topics conducive to semantic search or that produced technologies adopted by this field, such as “text processing”, “electronic commerce”, “digital libraries”, and “web browser”. This is an exemplary case of the dynamics exploited by Augur, in which some topics, previously less connected, started to collaborate and moulded a novel research area that inherited their domains (e.g., “information retrieval”, “digital libraries”), formats (e.g., “xml”), software (e.g., “search engines”), and applications (e.g., “content-based retrieval”). As part of the making sense process, in the table we also report the top 10 authors (top-right) and the top 5 papers (bottom) relevant to this cluster.
| Cluster | Influential Authors |
| world wide web, query languages, metadata, content-based retrieval, information retrieval, search engines, xml, information systems, information retrieval systems, multi agent systems, intelligent agents, servers, digital libraries, electronic commerce, text processing, information management, indexing, web browsers, classification | W. Bruce Croft, Dieter Fensel, Dan Suciu, William W. Cohen, Berthier Ribeiro-Neto, Clement T. Yu, James Allan, Justin Zobel, Dragomir R. Radev, Victor Vianu |
| Influential Papers | |
| – A Sheth et al. “Managing semantic content for the Web” (2002)- RWP Luk et al. “A survey in indexing and searching XML documents” (2002)
– J Kahan et al. “Annotea: An open RDF infrastructure for shared Web annotations” (2002) – R Manmatha et al. “Modeling score distributions for combining the outputs of search engines” (2001) – S Dagtas et al. “Models for motion-based video indexing and retrieval” (2000) |
|
This research has been the main objective of Angelo Salatino’s doctoral work, which started in Dec 2014. We are thankful to Springer Nature for funding this research.
RELEVANT PAPERS
- Salatino, Angelo A., Francesco Osborne, and Enrico Motta. “AUGUR: Forecasting the Emergence of New Research Topics“. In JCDL ’18: The 18th ACM/IEEE Joint Conference on Digital Libraries, June 3–7, 2018, Fort Worth, TX, USA, ACM, New York, NY, USA, Article 4, 10 pages.
- Salatino, Angelo A., Francesco Osborne, and Enrico Motta. “How are topics born? Understanding the research dynamics preceding the emergence of new areas.” PeerJ Computer Science 3 (2017): e119.
- Salatino, Angelo Antonio, and Enrico Motta. “Detection of Embryonic Research Topics by Analysing Semantic Topic Networks.” International Workshop on Semantic, Analytics, Visualisation. Springer, Cham, 2016.
- Salatino, Angelo Antonio. “Early Detection and Forecasting of Research Trends.” ISWC-DC 2015 The ISWC 2015 Doctoral Consortium (2015): 49.